Jokowi Dikira Monyet, Kulit Hitam Dikira Gorila, Google Masih Harus "Sekolah"
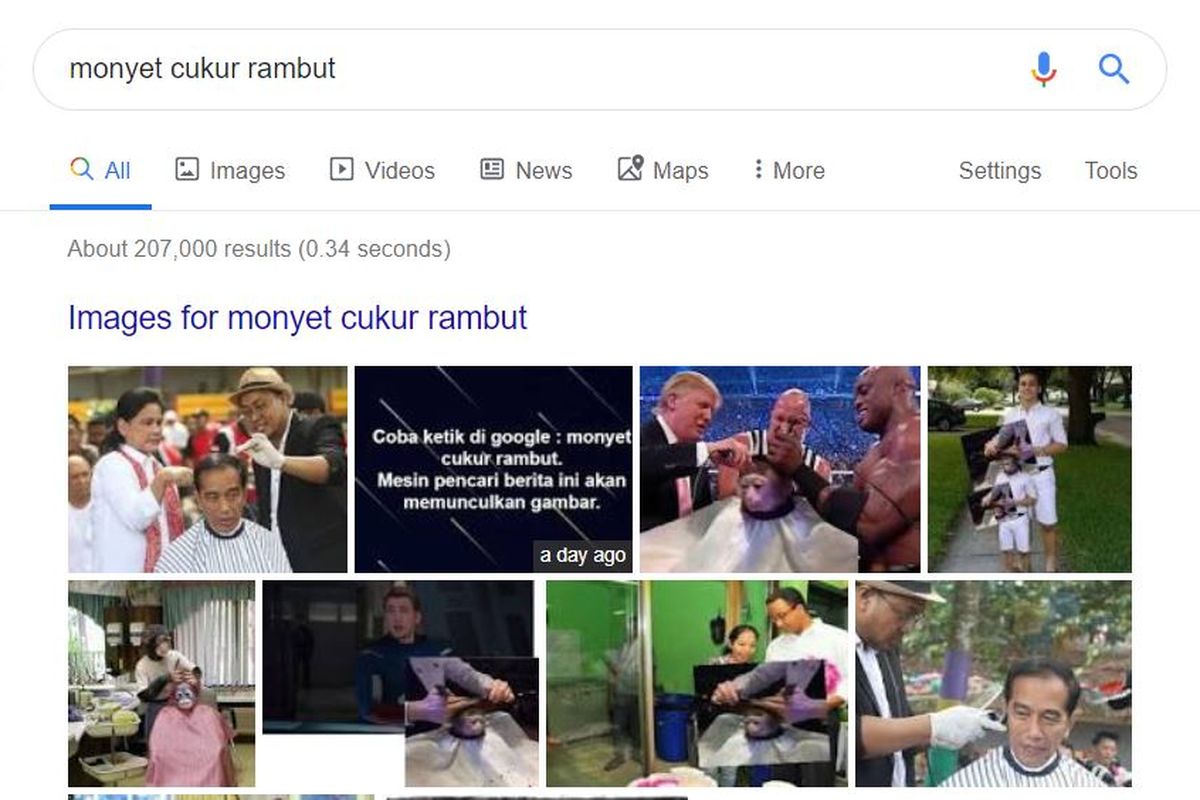
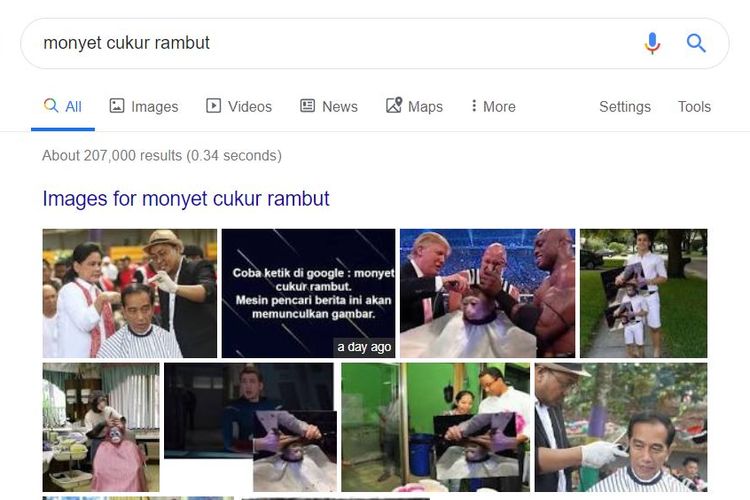

KOMPAS.com – Munculnya foto-foto Presiden Joko Widodo ketika netizen mengetik “monyet cukur rambut” bukan skandal baru bagi Google. Pada 2015, alogaritma Google pernah membuat kesalahan serupa dengan salah mengira orang kulit hitam sebagai gorila.
Dilansir dari Wired, 11 Januari 2018; skandal itu bermula ketika seorang pengembang software berkulit hitam menulis di Twitter bahwa Google Photos melabeli foto dirinya dan temannya yang juga berkulit hitam sebagai “gorillas” (gorila).
Untuk diketahui, aplikasi dan situs Google Photos, merupakan layanan penyimpanan foto yang telah digunakan oleh 500 juta orang. Google Photos dilengkapi dengan teknologi kecerdasan buatan untuk mengelompokkan foto secara otomatis agar penggunanya lebih mudah ketika mencari foto dengan konten serupa, misalnya danau, kopi atau dalam kasus kali ini, gorila.
Menyusul kejadian tersebut, Google meminta maaf dan memutuskan untuk menyensor kata “gorilla” agar tidak bisa digunakan pada foto dengan dua subyek atau lebih. Selain gorila, “chimp” atau “chimpanzee” (simpanse) dan “monkey” (monyet) juga ikutan diblokir oleh Google Photos.
Baca juga: Kisah Deepmind, AI Terbaik Google yang Gagal Ujian Matematika SMA
Padahal, Wired yang menguji coba aplikasi tersebut pada 2018 bisa mencari foto dengan kata kunci “baboon” (babun), “gibbon” (ungka), “marmoset” dan “orangutan”. Mereka menulis bahwa “capuchin” dan “colobus” juga bisa digunakan selama tidak dibarengi dengan “monkey”.
Intinya, akibat kejadian tahun 2015 tersebut, seekor babun adalah babun bagi Google Photos, tetapi seekor monyet bukan monyet bagi teknologi ini. Sementara itu, gorila dan simpanse sama sekali tidak dapat dikenali oleh Google Photos.
“Teknologi pelabelan foto masih sangat awal dan sayangnya, jauh dari sempurna,” tulis juru bicara Google kepada Wired.
Google Photos, y'all fucked up. My friend's not a gorilla. pic.twitter.com/SMkMCsNVX4
— Jacky wants to be Static Shock for SDCC 2020 (@jackyalcine) June 29, 2015
Bagi Anda, apa yang dilakukan oleh Google ini mungkin terdengar konyol. Namun, sebetulnya apa yang dilakukan oleh raksasa teknologi tersebut adalah sesuatu yang logis mengingat berbagai kekurangan teknologi pembelajaran mesin saat ini.
Dengan data yang cukup banyak dan kemampuan komputerisasi yang memadai, sebuah AI bisa memang dilatih untuk mengenali foto atau mentranskripsikan sebuah pidato. Namun, ketika mendapati skenario di luar formulanya, AI tidak memiliki akal sehat atau konsep abstrak untuk menanggapinya dengan tepat.
Oleh karena itulah, para insinyur yang merancang AI juga harus mulai memikirkan kasus-kasus yang mungkin terjadi di luar data pelatihan mereka.
Sayangnya, seperti yang dikatakan oleh profesor University of Virginia Vicente Ordóñez Román, sulit untuk memprediksikan semua skenario yang mungkin terjadi sebelum sistem mulai dijalankan. Para insinyur mungkin baru akan menemuinya setelah sistem diaktifkan.
Simak breaking news dan berita pilihan kami langsung di ponselmu. Pilih saluran andalanmu akses berita Kompas.com WhatsApp Channel : https://www.whatsapp.com/channel/0029VaFPbedBPzjZrk13HO3D. Pastikan kamu sudah install aplikasi WhatsApp ya.
-
![]()
Kolaborasi NASA dan AI Google Temukan Tata Surya Mini Mirip Bumi
-
![]()
Akurat 95 Persen, AI Google Bisa Prediksi Kapan Seseorang Meninggal
-
![]()
Lewat Google, Misteri Sumber Gas Terlarang CFC-11 Terpecahkan
-
![]()
Bagaimana Google Trends Bisa Bantu Monitoring Demam Berdarah?
-
![]()
Kisah Deepmind, AI Terbaik Google yang Gagal Ujian Matematika SMA












Video Pilihan Video Lainnya >
Terkini Lainnya






















